这是Java序列化机制及源码解读系列的第二篇,主要学习源码处理对象输出流的方法。接下来会先学习ObjectOutputStream的父类,然后再探究ObjectOutputStream。
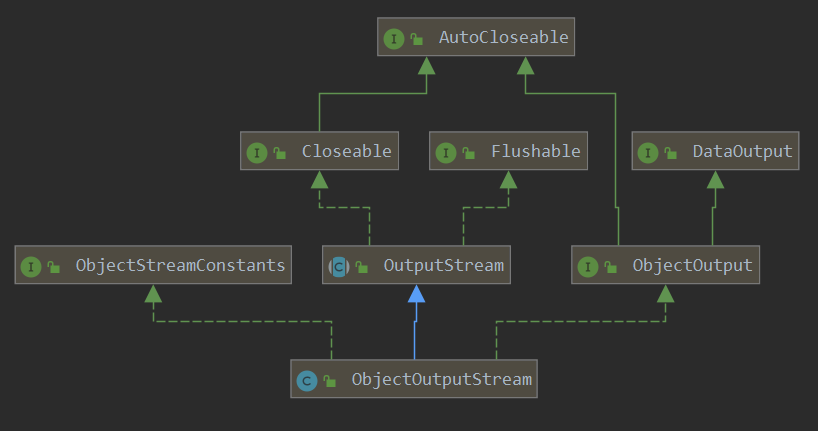
1 2 public class ObjectOutputStream extends OutputStream implements ObjectOutput , ObjectStreamConstants
学习ObjectOutputStream前,先了解下其父类。
一、DataOutput DataOutput接口提供将数据从任何Java基本类型(byte、short、int、long、float、double、char、boolean)转换为一系列字节,并将这些字节写入二进制流。 还有一种将String转换为modified UTF-8格式并编写结果字节系列的功能。
DataOutput定义了以下接口方法:
Modifier and Type
Method and Description
void
write(byte[] b):将输出流写入数组 b中的所有字节。
void
write(byte[] b, int off, int len):从阵列 b写入 len字节,以输出流。
void
write(int b):向输出流写入参数 b的八个低位。
void
writeBoolean(boolean v):将 boolean值写入此输出流。
void
writeByte(int v):向输出流写入参数 v的八个低位位。
void
writeBytes(String s):将一个字符串写入输出流。
void
writeChar(int v):将两个字节组成的 char值写入输出流。
void
writeChars(String s):写入每一个字符在字符串中 s ,到输出流中,为了,每个字符使用两个字节。
void
writeDouble(double v):将 double值(由8个字节组成)写入输出流。
void
writeFloat(float v):将 float值写入输出流,该值由四个字节组成。
void
writeInt(int v):将 int值(由四个字节组成)写入输出流。
void
writeLong(long v):将 long值(由八个字节组成)写入输出流。
void
writeShort(int v):将两个字节写入输出流以表示参数的值。
void
writeUTF(String s):将两个字节的长度信息写入输出流,其后是 字符串 s中每个字符的 s 。
二、ObjectOutput ObjectOutput扩展了DataOutput接口,除了原始类型外还添加了对象、数组和字符串的输出流。
Modifier and Type
Method and Description
void
close():关闭流。
void
flush():刷新流。
void
write(byte[] b):写入一个字节数组。
void
write(byte[] b, int off, int len):写入一个子字节数组。
void
write(int b):写一个字节。
void
writeObject(Object obj):将对象写入底层存储或流。
三、OutputStream 这个抽象类是表示字节输出流的所有类的超类。输出流接收输出字节并将其发送到某个接收器。
需要定义OutputStream子类的应用OutputStream必须至少提供一个写入一个字节输出的方法。
Modifier and Type
Method and Description
void
close():关闭此输出流并释放与此流相关联的任何系统资源。
void
flush():刷新此输出流并强制任何缓冲的输出字节被写出。
void
write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。
void
write(byte[] b, int off, int len):从指定的字节数组写入 len个字节,从偏移 off开始输出到此输出流。
void
write(int b):将指定的字节写入此输出流。
void
writeObject(Object obj):将对象写入底层存储或流。
四、ObjectStreamConstants ObjectStreamConstants定义了一系列的常量,用来表示对象进行序列化时单个字节数据的含义,方便后续序列化和反序列化按照此规范进行。
Modifier and Type
Field
Description
Value
static short
STREAM_MAGIC
魔术头,标记序列化协议的信息
0xaced
static short
STREAM_VERSION
标记序列化协议的版本信息
0x0005
static byte
TC_BASE
第一个标签值
0x70
static byte
TC_NULL
Null对象引用,父类描述符标识
0x70
static byte
TC_REFERENCE
流中已存在对象的引用
0x71
static byte
TC_CLASSDESC
new class类描述符
0x72
static byte
TC_OBJECT
new 对象
0x73
static byte
TC_STRING
new String字符串
0x74
static byte
TC_ARRAY
new 数组
0x75
static byte
TC_CLASS
类引用
0x76
static byte
TC_BLOCKDATA
字节跟随标记表示此块数据中的字节数
0x77
static byte
TC_ENDBLOCKDATA
一个对象的可选数据块的结尾
0x78
static byte
TC_RESET
重置流上下文
0x79
static byte
TC_BLOCKDATALONG
long类型数据块,标记long类型数据块的数量
0x7A
static byte
TC_EXCEPTION
写过程发生异常
0x7B
static byte
TC_LONGSTRING
long字符串
0x7C
static byte
TC_PROXYCLASSDESC
new 代理类描述符
0x7D
static byte
TC_ENUM
new 枚举常量
0x7E
static byte
TC_MAX
最后一个标签值
0x7E
static int
baseWireHandle
分配的第一个句柄
0x7e0000
static byte
SC_WRITE_METHOD
对于objectstreamclass标志位屏蔽。表示一个可序列化的类自定义了writeObject()
0x01
static byte
SC_SERIALIZABLE
对于objectstreamclass标志位屏蔽。显示类的序列化,实现Serializable
0x02
static byte
SC_EXTERNALIZABLE
对于objectstreamclass标志位屏蔽。指示类是外部的,实现Externalizable
0x04
static byte
SC_BLOCK_DATA
对于objectstreamclass标志位屏蔽。说明写的块数据模式的外部数据
0x08
static byte
SC_ENUM
对于objectstreamclass标志位屏蔽。指出类是一个枚举类型,Enum
0x10
static int
PROTOCOL_VERSION_1
流协议的版本
0x0001
static int
PROTOCOL_VERSION_2
流协议的版本
0x0002
static SerializablePermission
SUBCLASS_IMPLEMENTATION_PERMISSION
允许重写 readObject 和 writeObject
new SerializablePermission(“enableSubclassImplementation”);
static SerializablePermission
SUBSTITUTION_PERMISSION
允许在序列化/反序列化期间使用一个对象取代另一个对象。
new SerializablePermission(“enableSubstitution”);
五、ObjectOutputStream ObjectOutStream有7个内部类,其作用如下:
BlockDataOutputStream Java基本数据类型的写入流实现
Caches 用于安全审计缓存
DebugTraceInfoStack 堆栈保存有关序列化进程状态的调试信息,以便嵌入异常消息
HandleTable 保存对象及其句柄的映射关系 作用是缓存写过的共享class便于下次查找
ReplaceTable 替换对象的映射关系
PutField和PutFieldImpl 动态修改序列化的字段
先着重分析下BlockDataOutputStream,再分析ObjectOutputStream的方法及序列化流程。
1、静态内部类BlockDataOutputStream-Java基本数据类型的写入流实现 1 2 private static class BlockDataOutputStream extends OutputStream implements DataOutput
BlockDataOutputStream实现了DataOutput并且继承了OutputStream,该类主要用来将数据从Java基本类型转换字节流并写入底层数据流。
缓冲输出流有两种模式:在默认模式下,输出数据和DataOutputStream使用同样模式;在块数据模式下,使用一个缓冲区来缓存数据到达最大长度或者手动刷新时将内容写入底层数据流,块模式在写数据之前,要先写入一个头部来表示当前块的长度。
从内部变量和构造函数中可以看出,缓冲区的大小是固定且不可修改的,其中包含了一个下层输入流和一个数据输出流以及是否采用块模式的标识,在构造时默认不采用块数据模式。
1.1、BlockDataOutputStream构造方法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 private static class BlockDataOutputStream extends OutputStream implements DataOutput { private static final int MAX_BLOCK_SIZE = 1024 ; private static final int MAX_HEADER_SIZE = 5 ; private static final int CHAR_BUF_SIZE = 256 ; private final byte [] buf = new byte [MAX_BLOCK_SIZE]; private final byte [] hbuf = new byte [MAX_HEADER_SIZE]; private final char [] cbuf = new char [CHAR_BUF_SIZE]; private boolean blkmode = false ; private int pos = 0 ; private final OutputStream out; private final DataOutputStream dout; BlockDataOutputStream(OutputStream out) { this .out = out; dout = new DataOutputStream(this ); }
1.2、块数据模式及底层流数据写入 BlockDataOutputStream定义了两个方法用于设置和获取块数据模式:setBlockDataMode可以改变当前的数据模式,从块数据模式切换到非块数据模式时,要将缓冲区内的数据写入到底层流;getBlockDataMode查询当前块数据模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 boolean setBlockDataMode (boolean mode) throws IOException if (blkmode == mode) { return blkmode; } drain(); blkmode = mode; return !blkmode; } boolean getBlockDataMode () return blkmode; }
drain在多个方法中被调用,作用是将缓冲区内的数据全部写入底层流 ,但不会刷新底层流,在写入实际数据前要先用writeBlockHeader写入块头部,头部包含1字节标识位和1字节或4字节的长度大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void drain () throws IOException if (pos == 0 ) { return ; } if (blkmode) { writeBlockHeader(pos); } out.write(buf, 0 , pos); pos = 0 ; } private void writeBlockHeader (int len) throws IOException if (len <= 0xFF ) { hbuf[0 ] = TC_BLOCKDATA; hbuf[1 ] = (byte ) len; out.write(hbuf, 0 , 2 ); } else { hbuf[0 ] = TC_BLOCKDATALONG; Bits.putInt(hbuf, 1 , len); out.write(hbuf, 0 , 5 ); } }
通用数据流写入的处理方法:write主要是写入到缓冲区 ,写入前都需要先检查缓冲区有没有达到上限,达到时需要先刷新,然后再将数据复制到缓冲区。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public void write (int b) throws IOException if (pos >= MAX_BLOCK_SIZE) { drain(); } buf[pos++] = (byte ) b; } public void write (byte [] b) throws IOException write(b, 0 , b.length, false ); } public void write (byte [] b, int off, int len) throws IOException write(b, off, len, false ); } void write (byte [] b, int off, int len, boolean copy) throws IOException if (!(copy || blkmode)) { drain(); out.write(b, off, len); return ; } while (len > 0 ) { if (pos >= MAX_BLOCK_SIZE) { drain(); } if (len >= MAX_BLOCK_SIZE && !copy && pos == 0 ) { writeBlockHeader(MAX_BLOCK_SIZE); out.write(b, off, MAX_BLOCK_SIZE); off += MAX_BLOCK_SIZE; len -= MAX_BLOCK_SIZE; } else { int wlen = Math.min(len, MAX_BLOCK_SIZE - pos); System.arraycopy(b, off, buf, pos, wlen); pos += wlen; off += wlen; len -= wlen; } } } public void flush () throws IOException drain(); out.flush(); } public void close () throws IOException flush(); out.close(); }
1.3、BlockDataOutputStream处理基元数据输出方法: 剩余写不同基元数据的方法到缓冲区都类似,write[Type]和write[Type]s一个是处理单个基元数据和一组连续基元数据的情况,write[Type]s相对来说更加优化,以便更有效地写入一组基元数据值或者处理写基元类型的数组,其优化的方式是先计算出缓冲区内的剩余大小,计算可以写入的个数,然后直接写入而不是每次写入之前检查缓冲区是否有空间,减少判断次数。
下面以writeInt和writeInts对Int类型的写入方法深入探究下,其它方法类似不再赘诉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public void writeInt (int v) throws IOException if (pos + 4 <= MAX_BLOCK_SIZE) { Bits.putInt(buf, pos, v); pos += 4 ; } else { dout.writeInt(v); } } void writeInts (int [] v, int off, int len) throws IOException int limit = MAX_BLOCK_SIZE - 4 ; int endoff = off + len; while (off < endoff) { if (pos <= limit) { int avail = (MAX_BLOCK_SIZE - pos) >> 2 ; int stop = Math.min(endoff, off + avail); while (off < stop) { Bits.putInt(buf, pos, v[off++]); pos += 4 ; } } else { dout.writeInt(v[off++]); } } }
除了write[Type]和write[Type]s,还有writeUTF 写UTF8格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void writeUTF (String s, long utflen) throws IOException if (utflen > 0xFFFFL ) { throw new UTFDataFormatException(); } writeShort((int ) utflen); if (utflen == (long ) s.length()) { writeBytes(s); } else { writeUTFBody(s); } }
2、序列化导读 在开始分析writeObject前,再来强调下,Java序列化时只能序列化该对象的类信息、属性及其值,不能序列化对象的方法 ,JAVA序列化了类信息以后也就可以通过类调用其方法了。所以最终writeObject序列化后的结果一定是类信息和属性的序列化。
为了方便后面writeObject的分析,先看下一个序列化的例子:
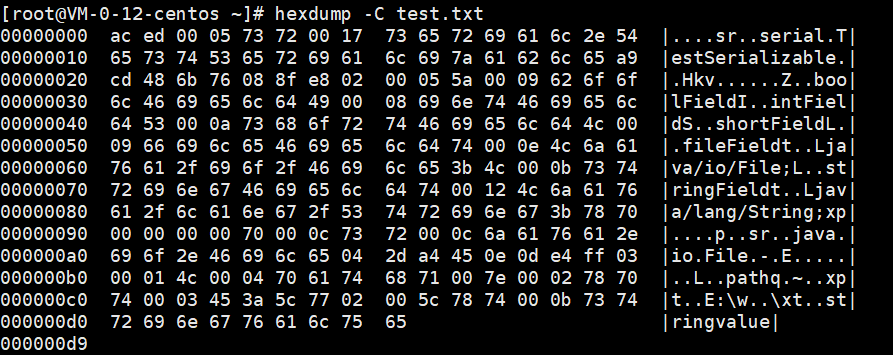
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package serial;import java.io.*;class TestSerializable implements Serializable private static final long serialVersionUID = -6211228684695072792L ; private int intField = 112 ; private boolean boolField = false ; private short shortField = 12 ; private String stringField = "stringvalue" ; private File fileField = new File("E:\\" ); public final void test () System.out.println("test" ); } } public class Main public static void main (String[] args) throws Exception TestSerializable testSerializable = new TestSerializable(); ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("e:\\test.txt" ))); oos.writeObject(testSerializable); System.out.println("对象序列化成功!" ); oos.flush(); oos.close(); } }
序列化后的文件输出结果如下图:
虽然序列化后的信息看起来比较乱,但是还是能得到一些信息的
类的全称serial.TestSerializable
属性类型及属性名和Z和boolField(Z代表boolean类型,后续会提到)
属性类型及属性名I和intField(I代表Int类型,后续会提到)
属性类型及属性名S和shortField(S代表short类型,后续会提到)
属性名及属性类型fileField和java/io/File
属性名及属性类型stringField和java/lang/String
属性值E:\和stringvalue(当然还有其他值这里只说能看到的)
备注:后续分析时会将上面例子带入分析,以(例子分析:)形式备注在每一段分析的最后面。
3、ObjectOutputStream构造方法 3.1、有参构造: 首先把bout绑定到底层的字节数据容器,调用writeStreamHeader()方法完成序列化流头部信息的写入0xaced0005
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ObjectOutputStream (OutputStream out) throws IOException verifySubclass(); bout = new BlockDataOutputStream(out); handles = new HandleTable(10 , (float ) 3.00 ); subs = new ReplaceTable(10 , (float ) 3.00 ); enableOverride = false ; writeStreamHeader(); bout.setBlockDataMode(true ); if (extendedDebugInfo) { debugInfoStack = new DebugTraceInfoStack(); } else { debugInfoStack = null ; } }
写入魔术头和版本信息
1 2 3 4 5 protected void writeStreamHeader () throws IOException bout.writeShort(STREAM_MAGIC); bout.writeShort(STREAM_VERSION); }
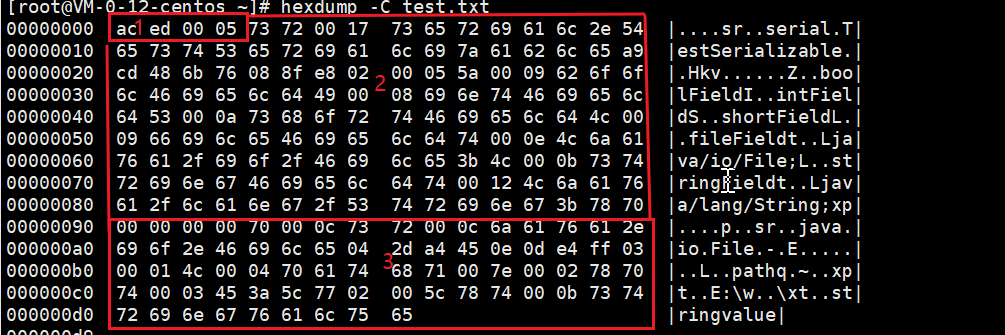
(例子分析:此时上面的例子写入了ac ed 00 05)
4、writeObject写入对象输出流 writeObject的调用
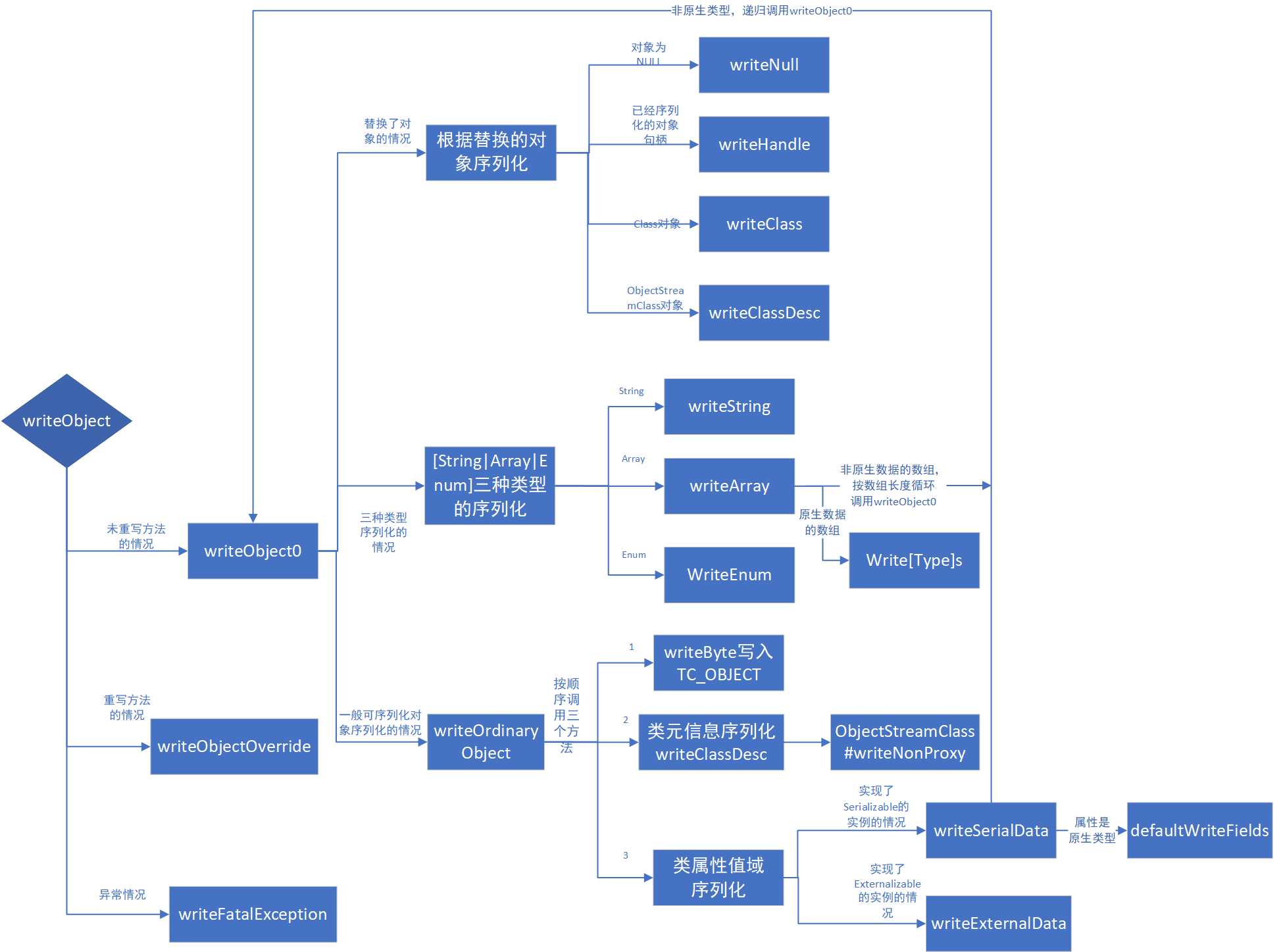
4.1、writeObject: writeObject 如果writeObject被重写会调用writeObjectOverride重写方法,否则调用 writeObject0方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public final void writeObject (Object obj) throws IOException if (enableOverride) { writeObjectOverride(obj); return ; } try { writeObject0(obj, false ); } catch (IOException ex) { if (depth == 0 ) { writeFatalException(ex); } throw ex; } }
writeFatalException:处理序列化异常情况下的序列化信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private void writeFatalException (IOException ex) throws IOException clear(); boolean oldMode = bout.setBlockDataMode(false ); try { bout.writeByte(TC_EXCEPTION); writeObject0(ex, false ); clear(); } finally { bout.setBlockDataMode(oldMode); } }
writeObject0: 序列化的核心方法,主要有三个步骤,1是处理不需要序列化的情况、2是判断是否替换了对象(有writeReplace方法)、3是处理其它情况 主要是String|Array|Enum和一般可序列化对象的序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 private void writeObject0 (Object obj, boolean unshared) throws IOException { boolean oldMode = bout.setBlockDataMode(false ); depth++; try { int h; if ((obj = subs.lookup(obj)) == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } Object orig = obj; Class<?> cl = obj.getClass(); ObjectStreamClass desc; for (;;) { Class<?> repCl; desc = ObjectStreamClass.lookup(cl, true ); if (!desc.hasWriteReplaceMethod() || (obj = desc.invokeWriteReplace(obj)) == null || (repCl = obj.getClass()) == cl) { break ; } cl = repCl; } if (enableReplace) { Object rep = replaceObject(obj); if (rep != obj && rep != null ) { cl = rep.getClass(); desc = ObjectStreamClass.lookup(cl, true ); } obj = rep; } if (obj != orig) { subs.assign(orig, obj); if (obj == null ) { writeNull(); return ; } else if (!unshared && (h = handles.lookup(obj)) != -1 ) { writeHandle(h); return ; } else if (obj instanceof Class) { writeClass((Class) obj, unshared); return ; } else if (obj instanceof ObjectStreamClass) { writeClassDesc((ObjectStreamClass) obj, unshared); return ; } } if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else { if (extendedDebugInfo) { throw new NotSerializableException( cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } } } finally { depth--; bout.setBlockDataMode(oldMode); } }
(例子分析:此时新写入任何数据,还是ac ed 00 05,按照示例代码,接下来会进入writeOrdinaryObject方法)
补充:ObjectStreamClass 在上面writeObject0代码,创建了一个用于类序列化描述符的ObjectStreamClass对象,我们先大体分析下ObjectStreamClass。
官方文档是这样描述这个类的:
类的序列化描述符。 它包含该类的名称和serialVersionUID。 以使用lookup方法查找/创建Java Java中加载的特定类的ObjectStreamClass。
除了内部类外它具有以下方法:
1 2 3 4 5 6 7 8 forClass():返回此版本映射到的本地VM中的类。 getField(String name):通过名称获取此类的字段。 getFields():返回此可序列化类的字段数组。 getName():返回此描述符描述的类的名称。 getSerialVersionUID():返回此类的serialVersionUID。 lookup(类<?> cl):找到可以序列化的类的描述符。 lookupAny(类<?> cl):返回任何类的描述符,无论它是否实现Serializable。 toString():返回描述此ObjectStreamClass的字符串。
通过以上方法ObjectStreamClass对象可以获取Class、类名称、类属性数组、类的serialVersionUID等。
了解了ObjectStreamClass,继续回到我们的分析。
三种类型的序列化 write[String|Array|Enum]: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 private void writeString (String str, boolean unshared) throws IOException handles.assign(unshared ? null : str); long utflen = bout.getUTFLength(str); if (utflen <= 0xFFFF ) { bout.writeByte(TC_STRING); bout.writeUTF(str, utflen); } else { bout.writeByte(TC_LONGSTRING); bout.writeLongUTF(str, utflen); } } private void writeArray (Object array, ObjectStreamClass desc, boolean unshared) throws IOException { bout.writeByte(TC_ARRAY); writeClassDesc(desc, false ); handles.assign(unshared ? null : array); Class<?> ccl = desc.forClass().getComponentType(); if (ccl.isPrimitive()) { if (ccl == Integer.TYPE) { int [] ia = (int []) array; bout.writeInt(ia.length); bout.writeInts(ia, 0 , ia.length); } else if (ccl == Byte.TYPE) { byte [] ba = (byte []) array; bout.writeInt(ba.length); bout.write(ba, 0 , ba.length, true ); } else if (ccl == Long.TYPE) { long [] ja = (long []) array; bout.writeInt(ja.length); bout.writeLongs(ja, 0 , ja.length); } else if (ccl == Float.TYPE) { float [] fa = (float []) array; bout.writeInt(fa.length); bout.writeFloats(fa, 0 , fa.length); } else if (ccl == Double.TYPE) { double [] da = (double []) array; bout.writeInt(da.length); bout.writeDoubles(da, 0 , da.length); } else if (ccl == Short.TYPE) { short [] sa = (short []) array; bout.writeInt(sa.length); bout.writeShorts(sa, 0 , sa.length); } else if (ccl == Character.TYPE) { char [] ca = (char []) array; bout.writeInt(ca.length); bout.writeChars(ca, 0 , ca.length); } else if (ccl == Boolean.TYPE) { boolean [] za = (boolean []) array; bout.writeInt(za.length); bout.writeBooleans(za, 0 , za.length); } else { throw new InternalError(); } } else { Object[] objs = (Object[]) array; int len = objs.length; bout.writeInt(len); if (extendedDebugInfo) { debugInfoStack.push( "array (class \"" + array.getClass().getName() + "\", size: " + len + ")" ); } try { for (int i = 0 ; i < len; i++) { if (extendedDebugInfo) { debugInfoStack.push( "element of array (index: " + i + ")" ); } try { writeObject0(objs[i], false ); } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } } } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } } } private void writeEnum (Enum<?> en, ObjectStreamClass desc, boolean unshared) throws IOException { bout.writeByte(TC_ENUM); ObjectStreamClass sdesc = desc.getSuperDesc(); writeClassDesc((sdesc.forClass() == Enum.class) ? desc : sdesc, false); handles.assign(unshared ? null : en); writeString(en.name(), false ); }
序列化关键部分writeOrdinaryObject: Java 序列化普通对象保存了三部分的数据:类型信息序列化TC_OBJECT + 类信息序列化 writeClassDesc() + 类实例数据信息序列化。到这里终于可以看到 io 序列化流的操作了。这个方法主要是在 Externalizable 和 Serializable 的接口出现分支,如果实现了 Externalizable 接口并且类描述符非动态代理,则执行 writeExternalData,否则执行 writeSerialData。同时,这个方法会写类描述信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private void writeOrdinaryObject (Object obj, ObjectStreamClass desc, boolean unshared) throws IOException if (extendedDebugInfo) { debugInfoStack.push( (depth == 1 ? "root " : "" ) + "object (class \"" + obj.getClass().getName() + "\", " + obj.toString() + ")" ); } try { desc.checkSerialize(); bout.writeByte(TC_OBJECT); writeClassDesc(desc, false ); handles.assign(unshared ? null : obj); if (desc.isExternalizable() && !desc.isProxy()) { writeExternalData((Externalizable) obj); } else { writeSerialData(obj, desc); } } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } }
(例子分析:加入TC_OBJECT 0x73,当前流为ac ed 00 05 73,接下来调用writeClassDesc来写入类信息)
为了方便阅读,下面将根据两部分进行解析,一是类信息序列化 writeClassDesc(),一是类实例数据信息序列化writeExternalData/ writeSerialData。
4.2、类元信息序列化 writeClassDesc() writeClassDesc-序列化类信息: writeClassDesc序列化类信息,序列化时会先递归调用 writeClassDesc 方法,将实现 Serializable 接口的父类信息也会同时序列化。类信息都保存在 ObjectStreamClass 类中,同时也可以通过 ObjectStreamClass#getFields 获取所有要序列的字段信息 ObjectStreamField。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 private void writeClassDesc (ObjectStreamClass desc, boolean unshared) throws IOException int handle; if (desc == null ) { writeNull(); } else if (!unshared && (handle = handles.lookup(desc)) != -1 ) { writeHandle(handle); } else if (desc.isProxy()) { writeProxyDesc(desc, unshared); } else { writeNonProxyDesc(desc, unshared); } } private void writeNonProxyDesc (ObjectStreamClass desc, boolean unshared) throws IOException bout.writeByte(TC_CLASSDESC); handles.assign(unshared ? null : desc); if (protocol == PROTOCOL_VERSION_1) { desc.writeNonProxy(this ); } else { writeClassDescriptor(desc); } Class<?> cl = desc.forClass(); bout.setBlockDataMode(true ); if (cl != null && isCustomSubclass()) { ReflectUtil.checkPackageAccess(cl); } annotateClass(cl); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); writeClassDesc(desc.getSuperDesc(), false ); }
(例子分析:加入TC_CLASSDESC 0x72,当前流为ac ed 00 05 73 72,接下来调用writeNonProxy来写入类信息)
ObjectStreamClass#writeNonProxy:写入实际的类元信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 void writeNonProxy (ObjectOutputStream out) throws IOException out.writeUTF(name); out.writeLong(getSerialVersionUID()); byte flags = 0 ; if (externalizable) { flags |= ObjectStreamConstants.SC_EXTERNALIZABLE; int protocol = out.getProtocolVersion(); if (protocol != ObjectStreamConstants.PROTOCOL_VERSION_1) { flags |= ObjectStreamConstants.SC_BLOCK_DATA; } } else if (serializable) { flags |= ObjectStreamConstants.SC_SERIALIZABLE; } if (hasWriteObjectData) { flags |= ObjectStreamConstants.SC_WRITE_METHOD; } if (isEnum) { flags |= ObjectStreamConstants.SC_ENUM; } out.writeByte(flags); out.writeShort(fields.length); for (int i = 0 ; i < fields.length; i++) { ObjectStreamField f = fields[i]; out.writeByte(f.getTypeCode()); out.writeUTF(f.getName()); if (!f.isPrimitive()) { out.writeTypeString(f.getTypeString()); } } }
根据上面代码可以看出,writeNonProxy主要作用是写入类信息和属性信息,具体会写入类长度+类名称+SerialVersionUID+类本身序列化的接口类型如SC_SERIALIZABLE+属性个数+每个属性信息
(例子分析:不算属性信息截至目前写入ac ed 00 05 73 72 00 17 73 65 72 69 61 6c 2e 54 65 73 74 53 65 72 69 61 6c 69 7a 61 62 6c 65 a9 cd 48 6b 76 08 8f e8 02 00 05。接下来分析循环属性完成写属性的信息,循环写入5个属性信息,分别是intField:I+长度0x0008+intField 即 49 00 08 69 6e 74 46 69 65 6c 64,boolField:Z+属性长度0x0009+boolField 即5a 00 09 62 6f 6f 6c 46 69 65 6c 64,shortField:S+长度0x000a+shortField 即 53 00 0a 73 68 6f 72 74 46 69 65 6c 64,fileField:L+属性名长度0x0009+fileField+TC_STRING + 类型长度0x0012+Ljava/io/File; 即 4c 00 09 66 69 6c 65 46 69 65 6c 64 74 00 0e 4c 6a 61 76 61 2f 69 6f 2f 46 69 6c 65 3b,stringField:L+长度0x000b+stringField+TC_STRING + 类型长度0x0012+Ljava/lang/String; 即 4c 00 0b 73 74 72 69 6e 67 46 69 65 6c 64 74 00 12 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69 6e 67 3b。因为原生类型属性信息和非原生类型属性信息位置是不一定的,所以属性信息在流的拼接后的具体信息不能确定。,最后不能忘了加上数据块结束标识TC_ENDBLOCKDATA 0x78)
补充:ObjectStreamField 在上面writeNonProxy序列化类属性信息时,创建了一个用于类的可序列化属性字段描述的ObjectStreamField实例,我们先大体分析下它。
官方文档是这样描述这个类的:
类的可序列化属性的描述。ObjectStreamFields的数组用于声明一个类的可序列化字段。
除了内部类外它具有以下public方法,通过以下方法可以获取某个属性的名称、类型等。
1 2 3 4 5 6 7 8 9 compareTo(Object obj):将此字段与另一个 ObjectStreamField进行比较。 getName():获取此字段的名称。 getOffset():实例数据内的字段偏移量。 getType():获取字段的类型。 getTypeCode():返回字段类型的字符编码。 getTypeString():返回JVM类型签名。 isPrimitive():如果此字段具有原始类型,则返回true 。 isUnshared():返回指示此ObjectStreamField实例表示的可序列化字段是否未共享的布尔值。 setOffset(int offset):实例数据偏移。
除了上面的方法,还有一些需要特别关注的方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 ObjectStreamField(Field field, boolean unshared, boolean showType) { this .field = field; this .unshared = unshared; name = field.getName(); Class<?> ftype = field.getType(); type = (showType || ftype.isPrimitive()) ? ftype : Object.class ; signature = getClassSignature(ftype).intern(); } private static String getClassSignature (Class<?> cl) StringBuilder sbuf = new StringBuilder(); while (cl.isArray()) { sbuf.append('[' ); cl = cl.getComponentType(); } if (cl.isPrimitive()) { if (cl == Integer.TYPE) { sbuf.append('I' ); } else if (cl == Byte.TYPE) { sbuf.append('B' ); } else if (cl == Long.TYPE) { sbuf.append('J' ); } else if (cl == Float.TYPE) { sbuf.append('F' ); } else if (cl == Double.TYPE) { sbuf.append('D' ); } else if (cl == Short.TYPE) { sbuf.append('S' ); } else if (cl == Character.TYPE) { sbuf.append('C' ); } else if (cl == Boolean.TYPE) { sbuf.append('Z' ); } else if (cl == Void.TYPE) { sbuf.append('V' ); } else { throw new InternalError(); } } else { sbuf.append('L' + cl.getName().replace('.' , '/' ) + ';' ); } return sbuf.toString(); } public String getTypeString () return isPrimitive() ? null : signature; }
截止到这里,类元信息已经序列化完成,接下来序列化类实例数据信息,即属性具体值的序列化。
4.3、类实例数据信息序列化writeExternalData/ writeSerialData writeSerialData&writeExternalData: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 private void writeSerialData (Object obj, ObjectStreamClass desc) throws IOException ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout(); for (int i = 0 ; i < slots.length; i++) { ObjectStreamClass slotDesc = slots[i].desc; if (slotDesc.hasWriteObjectMethod()) { PutFieldImpl oldPut = curPut; curPut = null ; SerialCallbackContext oldContext = curContext; if (extendedDebugInfo) { debugInfoStack.push( "custom writeObject data (class \"" + slotDesc.getName() + "\")" ); } try { curContext = new SerialCallbackContext(obj, slotDesc); bout.setBlockDataMode(true ); slotDesc.invokeWriteObject(obj, this ); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); } finally { curContext.setUsed(); curContext = oldContext; if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; } else { defaultWriteFields(obj, slotDesc); } } } private void writeExternalData (Externalizable obj) throws IOException PutFieldImpl oldPut = curPut; curPut = null ; if (extendedDebugInfo) { debugInfoStack.push("writeExternal data" ); } SerialCallbackContext oldContext = curContext; try { curContext = null ; if (protocol == PROTOCOL_VERSION_1) { obj.writeExternal(this ); } else { bout.setBlockDataMode(true ); obj.writeExternal(this ); bout.setBlockDataMode(false ); bout.writeByte(TC_ENDBLOCKDATA); } } finally { curContext = oldContext; if (extendedDebugInfo) { debugInfoStack.pop(); } } curPut = oldPut; }
属性值信息序列化的关键-默认属性值序列化方法defaultWriteFields: defaultWriteFields读取目标类中的属性值域,属性值是原生类型直接序列化到底层流,而非原生类型则需要递归调用writeObject0 来序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 private void defaultWriteFields (Object obj, ObjectStreamClass desc) throws IOException Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException(); } desc.checkDefaultSerialize(); int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte [primDataSize]; } desc.getPrimFieldValues(obj, primVals); bout.write(primVals, 0 , primDataSize, false ); ObjectStreamField[] fields = desc.getFields(false ); Object[] objVals = new Object[desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; desc.getObjFieldValues(obj, objVals); for (int i = 0 ; i < objVals.length; i++) { if (extendedDebugInfo) { debugInfoStack.push( "field (class \"" + desc.getName() + "\", name: \"" + fields[numPrimFields + i].getName() + "\", type: \"" + fields[numPrimFields + i].getType() + "\")" ); } try { writeObject0(objVals[i], fields[numPrimFields + i].isUnshared()); } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } } }
针对单独分析下
1 2 desc.getPrimFieldValues(obj, primVals); bout.write(primVals, 0 , primDataSize, false );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 void getPrimFieldValues (Object obj, byte [] buf) fieldRefl.getPrimFieldValues(obj, buf); } void getPrimFieldValues (Object obj, byte [] buf) if (obj == null ) { throw new NullPointerException(); } for (int i = 0 ; i < numPrimFields; i++) { long key = readKeys[i]; int off = offsets[i]; switch (typeCodes[i]) { case 'Z' : Bits.putBoolean(buf, off, unsafe.getBoolean(obj, key)); break ; case 'B' : buf[off] = unsafe.getByte(obj, key); break ; case 'C' : Bits.putChar(buf, off, unsafe.getChar(obj, key)); break ; case 'S' : Bits.putShort(buf, off, unsafe.getShort(obj, key)); break ; case 'I' : Bits.putInt(buf, off, unsafe.getInt(obj, key)); break ; case 'F' : Bits.putFloat(buf, off, unsafe.getFloat(obj, key)); break ; case 'J' : Bits.putLong(buf, off, unsafe.getLong(obj, key)); break ; case 'D' : Bits.putDouble(buf, off, unsafe.getDouble(obj, key)); break ; default : throw new InternalError(); } } }
(例子分析:第三部分属性值域序列化,按照之前每个属性信息序列化的顺序来写入其对应值,非原生属性值本例是00 00 00 00 70 00 0c,写入非原生类型的属性值,这里不再说明,自行调试)
六、总结-对象流输出规则
1、首先在序列化对象时,把序列化对象的信息分为三部分来存储,如上图:
第一部分是序列化头信息:用于描述序列化协议的信息和版本;
第二部分是类元信息的序列化:用于描述序列化类的名称,属性和父类的名称、属性;
第三部分是属性域的值的描述:用于记录当前类中属性的值。
2、第二部分描述的规则如下:
3、第三部分的描述规则:
4、在第二部分和第三部分都采用了递归的方式进行填充。
另外,Java序列化永远只会对类属性序列化 ,因为我们只要知道了类的全称,那么方法在内部都一样的,只管去调用就好了;在ObjectOutputStream中专门有一个内部类去处理原生类型的写入,所有的非原生类最终都是由原生类型组成的,非原生类归根结底还是原生类型,所以最终还是落到原生类型的序列化上面 。
更新-defaultWriteObject 我们在一些类重写writeObject时经常看到会调用defaultWriteObject方法,这里补充下。
方法很简单,在块模式中调用defaultWriteFields写入目标对象的属性域信息。
1 2 3 4 5 6 7 8 9 10 11 public void defaultWriteObject () throws IOException SerialCallbackContext ctx = curContext; if (ctx == null ) { throw new NotActiveException("not in call to writeObject" ); } Object curObj = ctx.getObj(); ObjectStreamClass curDesc = ctx.getDesc(); bout.setBlockDataMode(false ); defaultWriteFields(curObj, curDesc); bout.setBlockDataMode(true ); }
defaultWriteFields具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 private void defaultWriteFields (Object obj, ObjectStreamClass desc) throws IOException Class<?> cl = desc.forClass(); if (cl != null && obj != null && !cl.isInstance(obj)) { throw new ClassCastException(); } desc.checkDefaultSerialize(); int primDataSize = desc.getPrimDataSize(); if (primVals == null || primVals.length < primDataSize) { primVals = new byte [primDataSize]; } desc.getPrimFieldValues(obj, primVals); bout.write(primVals, 0 , primDataSize, false ); ObjectStreamField[] fields = desc.getFields(false ); Object[] objVals = new Object[desc.getNumObjFields()]; int numPrimFields = fields.length - objVals.length; desc.getObjFieldValues(obj, objVals); for (int i = 0 ; i < objVals.length; i++) { if (extendedDebugInfo) { debugInfoStack.push( "field (class \"" + desc.getName() + "\", name: \"" + fields[numPrimFields + i].getName() + "\", type: \"" + fields[numPrimFields + i].getType() + "\")" ); } try { writeObject0(objVals[i],fields[numPrimFields + i].isUnshared()); } finally { if (extendedDebugInfo) { debugInfoStack.pop(); } } } }
参考: Java API 8 https://www.cnblogs.com/yanggb/p/10664155.html https://blog.csdn.net/jenny_995368/article/details/99672570 https://developer.aliyun.com/article/636145 https://blog.csdn.net/weixin_33843947/article/details/89618157