一、基本概念: 集合可以看作是一种容器,用来存储对象信息 。所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下。
数组与集合的区别如下:
数组长度不可变化,集合类长度可变、用于保存数量不确定的数据;
树组无法保存具有映射关系的数据,集合可以保存具有映射关系的数据;
数组元素既可以是基本类型的值,也可以是对象;集合只能保存对象。
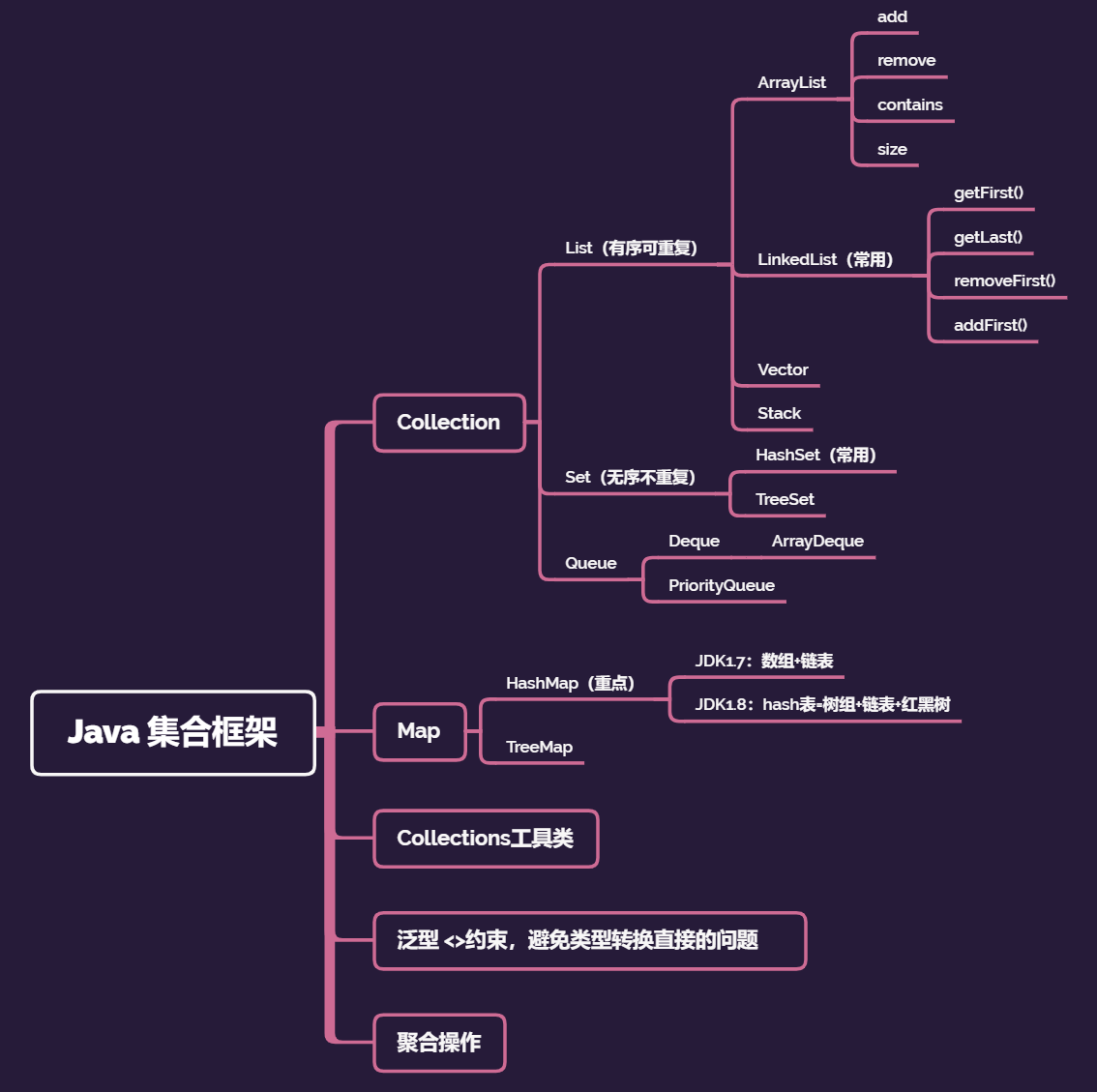
Java集合类主要由两个根接口Collection和Map 派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系,(注意:Map不是Collection的子接口)。其中List代表了有序可重复集合,可直接根据元素的索引来访问;Set代表无序不可重复集合,只能根据元素本身来访问;Queue是队列集合;Map代表的是存储key-value对的集合,可根据元素的key来访问value。
【以上概念来自:Java集合框架详解(全) 】
二、Collection 1 2 3 4 5 6 7 8 9 10 11 12 13 Collection |__List(有序可重复) | |__ ArrayList | |__ LinkedList(常用) | |__ Vector | |__ Stack |__ Set(无序不重复) | |__ HashSet(常用) | |__ TreeSet |__ Queue |__ Deque | |__ ArrayDeque |__ PriorityQueue
1、Collection Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素,Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
方法:
返回类型
方法名及描述
boolean
add(E e): 确保此集合包含指定的元素(可选操作)。
boolean
addAll(Collection<? extends E> c): 将指定集合中的所有元素添加到此集合(可选操作)。
void
clear(): 从此集合中删除所有元素(可选操作)。
boolean
contains(Object o): 如果此集合包含指定的元素,则返回 true 。
boolean
containsAll(Collection<?> c): 如果此集合包含指定 集合中的所有元素,则返回true。
boolean
equals(Object o): 将指定的对象与此集合进行比较以获得相等性。
int
hashCode(): 返回此集合的哈希码值。
boolean
isEmpty(): 如果此集合不包含元素,则返回 true 。
Iterator
iterator(): 返回此集合中的元素的迭代器。
default Stream
parallelStream(): 返回可能并行的 Stream与此集合作为其来源。
boolean
remove(Object o): 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。
boolean
removeAll(Collection<?> c): 删除指定集合中包含的所有此集合的元素(可选操作)。
default boolean
removeIf(Predicate<? super E> filter): 删除满足给定谓词的此集合的所有元素。
boolean
retainAll(Collection<?> c): 仅保留此集合中包含在指定集合中的元素(可选操作)。
int
size(): 返回此集合中的元素数。
default Spliterator
spliterator(): 创建一个Spliterator在这个集合中的元素。
default Stream
stream(): 返回以此集合作为源的顺序 Stream 。
Object[]
toArray(): 返回一个包含此集合中所有元素的数组。
T[] toArray(T[] a): 返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。
2、List List接口是一个有序 的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素 。
List 特点:有索引、顺序存储、可重复
2.1 ArrayList 1 2 3 public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
ArrayList:(java.util.ArrayList)ArrayList可以看作动态数组,底层数组实现的,相当于Array的复杂版本,它提供了动态的增加和减少元素,实现了ICollection和IList接口,灵活的设置数组的大小等好处
特点:查询快,增删慢(多线程)
ArrayList 实现 List 接口,所以能对它进行队列操作
ArrayList 实现 Deque 接口,能将LinkedList当作双端队列使用
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能克隆
ArrayList 实现了RandomAccess接口,可以快速随机存取,提高查询效率。
LinkedList 实现java.io.Serializable接口,所以LinkedList支持序列化,能通过序列化去传输
常用方法:
1 2 3 4 add():追加元素 remove():删除元素 contains():判断是否包含元素 size():元素个数
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public class Test public static void main (String[] args) throws IOException Test test = new Test(); test.arrayListTest(); } public void arrayListTest () throws IOException ArrayList<Person> personArrayList = new ArrayList<>(); Person person = new Person(new String[]{"netstat" ,"-ano" }); personArrayList.add(new Person(new String[]{"ipconfig" , "/a" })); personArrayList.add(person); System.out.println("--------------------------------------可通过索引获取----------------------------------" ); for (int i = 0 ; i < personArrayList.size(); i++) { Person p = personArrayList.get(i); p.run(); } System.out.println("--------------------------------------可通过迭代器获取--------------------------------" ); Iterator<Person> iterator = personArrayList.listIterator(); while (iterator.hasNext()){ Person p = iterator.next(); p.run(); } System.out.println("--------------------------------------可通过foreach获取--------------------------------" ); System.out.println(); for (Person p : personArrayList) { p.run(); } System.out.println("是否包含person? " + personArrayList.contains(person)); System.out.println("是否包含p? " + personArrayList.contains(new Person(new String[]{"netstat" ,"-ano" }))); System.out.println("移除第2个元素" ); personArrayList.remove(1 ); System.out.println("移除后长度: " + personArrayList.size()); personArrayList.clear(); System.out.println("清除后长度: " + personArrayList.size()); } } class Person implements Serializable public String[] cmd; Person(String[] cmd) { this .cmd = cmd; } public void run () throws IOException Runtime runtime = Runtime.getRuntime(); Process process = runtime.exec(this .cmd); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(process.getInputStream())); String s; StringBuffer stringBuffer = new StringBuffer(); for (String x : cmd) { stringBuffer.append(x); } System.out.println("**********************执行命令:" + stringBuffer + "********************************" ); while ((s = bufferedReader.readLine()) != null ) { System.out.println(s); } } }
2.2 LinkedList 1 2 3 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
特点:
底层链表实现的、查询慢、增删快
LinkedList的本质是双向链表 ,继承于AbstractSequentialLis
LinkedList 可以被当作堆栈、队列或双端队列 进行操作
LinkedList 实现 List 接口,所以能对它进行队列操作
LinkedList 实现 Deque 接口,能将LinkedList当作双端队列使用
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆
LinkedList 实现java.io.Serializable接口,所以LinkedList支持序列化,能通过序列化去传输
LinkedList 是非同步的。
常用方法:
1 2 3 4 5 6 7 8 9 10 11 12 add():添加元素 addFirst():在该列表开头插入指定的元素。 addLast():将指定的元素追加到此列表的末尾 getFirst():返回此列表中的第一个元素。 getLast():返回此列表中的最后一个元素。 removeFirst():从此列表中删除并返回第一个元素。 removeLast():从此列表中删除并返回最后一个元素。 descendingIterator():以相反的顺序返回此deque中的元素的迭代器 element():检索但不删除此列表的头(第一个元素) pop():从此列表表示的堆栈中弹出一个元素。 push():将元素推送到由此列表表示的堆栈上。 remove():删除元素。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class LinkedListTest public static void main (String[] args) throws IOException, ClassNotFoundException LinkedListTest linkedListTest = new LinkedListTest(); linkedListTest.linkedListTest(); } private void linkedListTest () throws IOException, ClassNotFoundException LinkedList<Person> linkedList = new LinkedList<>(); Person person = new Person(new String[]{"query" ,"user" }); linkedList.add(person); linkedList.add(0 ,new Person(new String[]{"systeminfo" })); linkedList.push(new Person(new String[]{"netstat" ,"-ano" })); Iterator<Person> iterator = linkedList.listIterator(); while (iterator.hasNext()) { iterator.next().run(); } System.out.println("———————————————————————————————————————————常用方法测试—————————————————————————————————————————" ); Person p1 = linkedList.getFirst(); System.out.println(p1.cmd); System.out.println(linkedList.size()); Person p2 = linkedList.pop(); System.out.println(p2.cmd); System.out.println(linkedList.size()); System.out.println(p1==p2); Person p3 = linkedList.removeLast(); System.out.println(p3.cmd); System.out.println(linkedList.size()); System.out.println("——————————————————————————————————————————————序列化测试——————————————————————————————————————" ); ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("E:\\1.txt" )); objectOutputStream.writeObject(linkedList); objectOutputStream.close(); ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("E:\\1.txt" )); LinkedList<Person> linkedList1 = (LinkedList<Person>) objectInputStream.readObject(); System.out.println(linkedList1.size()); } }
2.3 ArrayList和LinkedList使用场景 ArrayList在随机访问方面比较擅长,LinkedList在随机增删方面比较擅长
Q:那什么时候适合用list呢
对于需要快速插入,删除元素,应该使用LinkedList。Vector )。
2.4 Vector 1 2 3 public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
这里不赘述,具体可参考:https://www.cnblogs.com/msymm/p/9873551.html
2.5 Stack 1 class Stack<E> extends Vector<E>
Stack是栈,它的特性是:先进后出 (FILO, First In Last Out)。
java工具包中的Stack是继承于Vector的,由于Vector是通过数组实现的,这就意味着Stack也是通过数组实现的而非链表。当然,我们也可以将LinkedList当作栈来使用
这里不赘述,具体可参考:https://www.cnblogs.com/jpfss/p/11142612.html
3、Set Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。
特点:元素唯一、无序。
3.1 HashSet 1 2 3 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
HashSet 底层数据结构是哈希表,是元素为链表的数组,具有链表和数组的特点。HashSet不是线程安全的,集合元素可以是null。
初始容量16,加载因子0.75。
HashSet集合能够保证元素的唯一性是依靠元素类重写hashCode()方法和equals()方法来保证的,如果元素类不重写该方法,则存储该元素的集合不保证元素唯一。
HashSet底层用的是HashMap来存元素的。
hashCode()决定索引位置,如果该方法返回一个死值,会造成碰撞次数太多,效率太低。合理地重写hashCode()能有效减少碰撞次数。(对象之间对比的次数)
常用方法:
1 2 3 4 5 6 add(E e):添加元素 clear():移除所有元素 remove(Object o):移除指定元素 isEmpty():判断是否为空集合 contains(Object o):判断是否包含指定元素 size():元素个数
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class HashSetTest public static void main (String[] args) HashSetTest hashSetTest = new HashSetTest(); hashSetTest.hashSetTest(); } public void hashSetTest () HashSet<Person> hashSet = new HashSet<>(); System.out.println("---------------------重复元素仅添加一次-----------------------------" ); Person person = new Person(new String[]{"ipconfig" }); for (int i = 0 ; i < 5 ; i++) { hashSet.add(person); } System.out.println("set元素个数:" +hashSet.size()); System.out.println("---------------------判断是否包含person元素-------------------------" ); System.out.println(hashSet.contains(person)); System.out.println("---------------------移除person元素---------------------------------" ); System.out.println("移除中..." ); hashSet.remove(person); System.out.println("set元素个数:" +hashSet.size()); } }
3.2 TreeSet 1 2 public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable
TreeSet 底层数据结构是二叉数,元素唯一,最大的特点是能够对元素进行排序。
TreeSet不允许存null值
TreeSet 排序方式分为自然排序和比较器排序。具体使用哪种排序由调用的构造方法决定。空参构造使用的是自然排序,有参构造使用的比较器排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 add():将指定的元素添加到此集合(如果尚未存在)。 clear():清除元素 contains():如果此集合包含指定的元素,则返回 true 。 first():返回第一个元素 isEmpty():如果此集合不包含元素,则返回 true 。 last():返回最后一个元素 lower():返回这个集合中最大的元素严格小于给定的元素,如果没有这样的元素,则返回 null 。 floor():返回此集合中最大的元素小于或等于给定元素,如果没有这样的元素,则返回 null 。 ceiling():返回此集合中最小元素大于或等于给定元素,如果没有此元素,则返回 null 。 higher():返回严格大于给定元素的该集合中的最小元素,如果没有此元素则返回 null 。 remove():移除指定元素 size():元素个数 comparator():返回用于对该集合中的元素进行排序的比较器,或null,如果此集合使用其元素的natural ordering 。 headSet():返回该集合的部分的视图,其元素小于(或等于,如果 inclusive为真) toElement 。 subSet():返回该集合的部分的视图,其元素的范围从 fromElement到 toElement 。 tailSet():返回此组件的元素大于或等于 fromElement的部分的视图。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class TreeSetTest public static void main (String[] args) TreeSetTest treeSetTest = new TreeSetTest(); treeSetTest.treeSetTest(); } public void treeSetTest () TreeSet<String> treeSet = new TreeSet<>(); for (int i = 0 ; i < 5 ; i++) { treeSet.add("" + i); } System.out.println("---------------------判断是否包含2元素-------------------------" ); System.out.println(treeSet.contains("2" )); System.out.println("---------------------移除元素---------------------------------" ); System.out.println("移除中..." ); treeSet.remove("3" ); System.out.println("set元素个数:" +treeSet.size()); System.out.println("---------------------返回第一个元素---------------------------------" ); System.out.println(treeSet.first()); System.out.println("---------------------返回集合小于3的最大元素---------------------------------" ); System.out.println(treeSet.lower("3" )); System.out.println("---------------------返回集合大于3的最小元素---------------------------------" ); System.out.println(treeSet.higher("3" )); System.out.println("---------------------返回子集合---------------------------------" ); System.out.println(treeSet.subSet("2" ,"5" )); System.out.println("---------------------返回子集合:元素小于4---------------------------------" ); System.out.println(treeSet.headSet("4" )); } }
三、Map 1 2 3 Map |__ HashMap(重点) |__ TreeMap
1、Map
方法:
返回类型
方法及描述
void
clear(): 从该Map删除所有的映射(可选操作)。
default V
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction): 尝试计算指定键的映射及其当前映射的值(如果没有当前映射, null )。
default V
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction): 如果指定的键尚未与值相关联(或映射到 null ),则尝试使用给定的映射函数计算其值,并将其输入到此映射中,除非 null 。
default V
computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction): 如果指定的密钥的值存在且非空,则尝试计算给定密钥及其当前映射值的新映射。
boolean
containsKey(Object key): 如果此映射包含指定键的映射,则返回 true 。
boolean
containsValue(Object value): 如果此Map将一个或多个键映射到指定的值,则返回 true 。
Set<Map.Entry<K,V>>
entrySet(): 返回此Map包含的映射的Set视图。
boolean
equals(Object o): 将指定的对象与此映射进行比较以获得相等性。
default void
forEach(BiConsumer<? super K,? super V> action): 对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常。
V
get(Object key): 返回到指定键所映射的值,或 null如果此映射包含该键的映射。
default V
getOrDefault(Object key, V defaultValue): 返回到指定键所映射的值,或 defaultValue如果此映射包含该键的映射。
int
hashCode(): 返回此Map的哈希码值。
boolean
isEmpty(): 如果此Map不包含键值映射,则返回 true 。
Set
keySet(): 返回此Map包含的键的Set视图。
default V
merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction): 如果指定的键尚未与值相关联或与null相关联,则将其与给定的非空值相关联。
V
put(K key, V value): 将指定的值与该映射中的指定键相关联(可选操作)。
void
putAll(Map<? extends K,? extends V> m): 将指定Map的所有映射复制到此映射(可选操作)。
default V
putIfAbsent(K key, V value): 如果指定的键尚未与某个值相关联(或映射到 null )将其与给定值相关联并返回 null ,否则返回当前值。
V
remove(Object key): 如果存在(从可选的操作),从该Map删除一个键的映射。
default boolean
remove(Object key, Object value): 仅当指定的密钥当前映射到指定的值时删除该条目。
default V
replace(K key, V value): 只有当目标映射到某个值时,才能替换指定键的条目。
default boolean
replace(K key, V oldValue, V newValue): 仅当当前映射到指定的值时,才能替换指定键的条目。
default void
replaceAll(BiFunction<? super K,? super V,? extends V> function): 将每个条目的值替换为对该条目调用给定函数的结果,直到所有条目都被处理或该函数抛出异常。
int
size(): 返回此Map键值映射的数量。
Collection
values(): 返回此Map包含的值的Collection视图。
2、HashMap 1 2 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
HashMap 底层键的数据结构是哈希表,是元素为链表的数组,具有链表和数组的特点。键唯一且无序。HashMap允许使用 null 值和 null 键。
HashMap在JDK1.8之前采用的是数组加链表的形式实现其数据结构。
常用方法
1 2 3 4 5 6 7 8 9 10 11 通过put(key,value);方法添加元素 通过clear();清除集合 通过get(key);根据键获取值 通过remove(key);根据键移除这一组键值映射关系的数据 通过keySet();获取所有键的set集合 通过values();获取所有值的collection集合 通过entrySet();返回一个键值对的set集合 通过containsKey(key);判断集合中有没有键key 通过containsValue(values);判断集合中有没有值values 通过isEmpty();判断集合是否为空 通过size();获取集合中的键值对的对数
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class HashMapTest public static void main (String[] args) HashMapTest hashMapTest = new HashMapTest(); hashMapTest.hashMapTest(); } public void hashMapTest () HashMap<String, Object> hashMap = new HashMap<>(); Person person = new Person(new String[]{"query" , "user" }); for (int i = 0 ; i < 10 ; i++) { hashMap.put("" + i, person); } System.out.println("--------获取键为1的值--------------------------" ); Person p = (Person) hashMap.get("1" ); System.out.println(p); System.out.println("--------移除键为1的值--------------------------" ); Person p1 = (Person) hashMap.remove("1" ); System.out.println(p1); System.out.println("--------获取所有的键的集合---------------------" ); for (String s : hashMap.keySet()) { System.out.print(s + " " ); } System.out.println("\n" + "--------获取所有的键值对的集合-----------------" ); for (Map.Entry entry : hashMap.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } System.out.println("-------判断是否存在键为2的键值对---------------" ); System.out.println(hashMap.containsKey("2" )); System.out.println("-------判断是否存在值为person的键值对----------" ); System.out.println(hashMap.containsValue(person)); System.out.println("-------获取键值对个数--------------------------" ); System.out.println(hashMap.size()); System.out.println("-------清除所有元素----------------------------" ); System.out.println("清除中..." ); hashMap.clear(); System.out.println("-------判断map是否为空--------------------------" ); System.out.println(hashMap.isEmpty()); } }
3、TreeMap 1 2 3 public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap 键的数据结构是红黑树结构。键可以排序且唯一。TreeMap 键不允许插入null。
排序分为自然排序和比较器排序 ,线程是不安全的,但效率比较高
自然排序(空参构造)
常用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 put(K key, V value):将指定的值与此映射中的指定键相关联。 void clear():从地图中删除所有键值对。 void size():返回此映射中存在的键值对的数量。 void isEmpty():如果此映射不包含键-值映射,则返回true。 boolean containsKey(Object key):'true'如果地图中存在指定的键,则返回。 containsValue(对象键):返回'true'如果一个指定的值被映射到地图上的至少一个键。 Object get(Object key):检索value指定的映射key,如果此映射不包含键的映射,则返回null。 Object remove(Object key):从地图中删除指定键的键值对(如果存在)。 comparator comparator():返回用于对此映射中的键进行排序的比较器,如果此映射使用其键的自然顺序,则返回null。 Object firstKey():返回树映射中当前的第一个(最少)键。 Object lastKey():返回树映射中当前的最后一个(最大)键。 Object ceilingKey(Object key):返回大于或等于给定键的最小键,如果没有这样的键则返回null。 Object higherKey(Object key):返回严格大于指定键的最小键。 subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive):返回此地图部分的视图,其关键范围为 fromKey至 toKey NavigableMap descendingMap():返回此映射中包含的映射的逆序视图。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class TreeMapTest public static void main (String[] args) TreeMapTest treeMapTest = new TreeMapTest(); treeMapTest.treeMapTeet(); } public void treeMapTeet () TreeMap<String,Object> treeMap = new TreeMap<>(); treeMap.put("1" ,"中国" ); treeMap.put("2" ,"北京" ); treeMap.put("3" ,"河北" ); treeMap.put("4" ,"石家庄" ); System.out.println("-------获取键值对个数--------------------------" ); System.out.println(treeMap.size()); System.out.println("--------获取键为1的值--------------------------" ); System.out.println(treeMap.get("1" )); System.out.println("--------获取子地图-----------------------------" ); System.out.println(treeMap.subMap("2" ,"4" )); System.out.println("-------获取所有键值对--------------------------" ); System.out.println(treeMap.entrySet()); System.out.println("-------判断是否存在键为2的键值对---------------" ); System.out.println(treeMap.containsKey("2" )); System.out.println("-------判断是否存在值为河北的键值对----------" ); System.out.println(treeMap.containsValue("河北" )); System.out.println("-------清除所有元素----------------------------" ); System.out.println("清除中..." ); treeMap.clear(); System.out.println("-------判断map是否为空--------------------------" ); System.out.println(treeMap.isEmpty()); } }
四、集合常用类
概述:针对集合操作的工具类
常用方法
1 2 3 4 5 public static <T> void sort(List<T> list): 排序,默认按照自然顺序 public static <T> int binarySearch(List<?> list,T key): 二分查找 public static <T> T max(Collection<?> coll): 获取最大值 public static void reverse(List<?> list): 反转 public static void shuffle(List<?> list): 随机置换
参考链接:
https://www.kuangstudy.com/bbs/1374913932954726401 https://www.kuangstudy.com/bbs/1374914155043123201 https://www.cnblogs.com/bingyimeiling/p/10255037.html https://www.kuangstudy.com/bbs/1374621719079198721 https://www.kuangstudy.com/bbs/1382900026476445698 https://baijiahao.baidu.com/s?id=1675325359769184918&wfr=spider&for=pc https://blog.csdn.net/weixin_42139757/article/details/82108515